|
1 汉明码与TMR方案比较
在微小卫星的EDAC模块设计中,经常采用编码(主要是汉明码)或三倍冗余判决(Triple Modular Redundancy, TMR) 的方案。下面分别说明这两种方案并加以比较。
1.1 线性分组码
编码是在数据通信和数据存储领域广泛使用的检错/纠错方法。
线性分组码是使用很广泛的差错控制编码[1],其信息位和监督位的关联由一组线性代数方程组表示。 (n,k)线性分组码的编码就是建立由m(m=n-k)个生成冗余位的方程式构成的方程组,并由此线性方程组转化为k×n的生成矩阵G。编码时将信息位向量(k维)乘以生成矩阵G,即得到码字向量[Cn-1…C0],见式(1)。
[Cn-1,Cn-2,Λ,Cn-k,Cm-1,Λ,C0]=[Cn-1,Cn-2,Λ,Cn-k]×Gk×n (1)
将式(1)表示的方程组作移位变换,可以得到由式(2)表示的形式,H称为监督矩阵。解码时通过监督矩阵H与读出的码字向量C的乘积结果-校验子S来判断是否出错。当读出的码字向量C乘上H后得到一个零向量,表示没有出错;否则表示码字在存储之后发生了变化,即有错误发生。
S=Hm×n×[Cn-1,Λ,C0]T (2)
当码字中某位(单一位)发生错误时,会得到唯一的非零校验子S向量,该向量只与码字出错位置的图样有关,而与码字C无关。
汉明码是能纠正单个错误的线性分组码。其对应的G矩阵即为汉明码生成矩阵。这种编码下,分组编码总长是2m-1位,信息位长度是2m-m-1位,即(2m-1,2m-m-1)汉明码。(2m-1,2m-m-1)汉明码是编码效率最高的纠单错线性分组码。但考虑到一般计算机存储系统以字节为单位,而2m-m-1通常不是8的倍数,所以对汉明码加以扩展后,可以得到(12,8)、(22,16)等分组编码方案。这些方案具有一些新的特点,例如一种(22,16)方案可以做到纠单错、检双错,称作汉明SEC-DED码[2]。还可以通过优选,得到最佳监督矩阵H,使得运算电路最为简单、快速。
1.2 TMR
TMR的原理是将同一份信息保存在三份物理存储空间中。读取的时候比较三份内容,如果不完全相同,就取两个一致的值为真值。在CPU通过总线向内存写入数据 (WR有效) 时,每一比特数据通过三态门同时写到三个对应的比特存储单元中。当总线向内存请求数据 (RD有效) 时,三份同时存储的内容到达比较器,比较器逻辑按照前述规则输出数据内容及是否发生2/3判决的标记。根据总线要求,多路开关可以将数据内容或者每3比特比较器的2/3判决标记输出到总线上,后者可供分析研究可靠性时使用。
1.3 两种方案的比较
从存储空间的绝对大小角度考虑,编码方案比冗余判决方案要节省大量的存储空间。如果采用(22,16)汉明码,每1MB有效内存需要实际物理内存1.375MB。而采用TMR方案则需要3MB实际物理内存。
从系统的纠错可靠性角度考虑,首先假定内存的单粒子翻转事件(SEU)所发生的物理地址[3]和时间都是均匀分布的。设每一比特内存单元在单位时间内发生单粒子翻转的概率为σ。则每m比特内存结构中v比特发生SEU的概率为
σ(v,m)=Cvmσv(1-σ)m-v
采用(22,16)汉明码方案后,可以纠正每22比特内存行单元中的单比特错误。对于一行22比特编码记录,不发生SEU以及只有一比特发生SEU的概率和,即为该行内存单元的可靠性。因此,每22比特的行汉明码内存单元可靠性为:
ρ行ham=σ(0,22)+σ(1,22)=(1-σ)22+22σ(1-σ)21
每22比特行单元的有效容量是16位,即2个字节。故对于有效大小为N字节的汉明码内存系统,由N/2个行单元构成。其可靠性为:
ρham=ρ行hamN/2=[(1-σ)22+22σ(1-σ)21]N/2
而对于采用TMR的一行3比特的内存结构,可靠性为:
ρ行TMR=σ(0,3)+σ(1,3)=(1-σ)3+3σ(1-σ)2
对于一个有效大小为N字节的TMR内存系统,由8N个3比特结构组成,可靠性为
ρTMR=ρ行TMR8N=[(1-σ)3+3σ(1-σ)2]8N
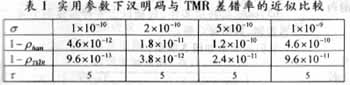
在实际航天应用中[3],通常10-9>σ>1010bit-1·s-1。取N=4×106(即4兆字节),表1给出了σ取不同值时差错率(1-ρ)的近似计算结果。其中差错率之比τ=(1-ρham)/(1-ρTMR)。 |